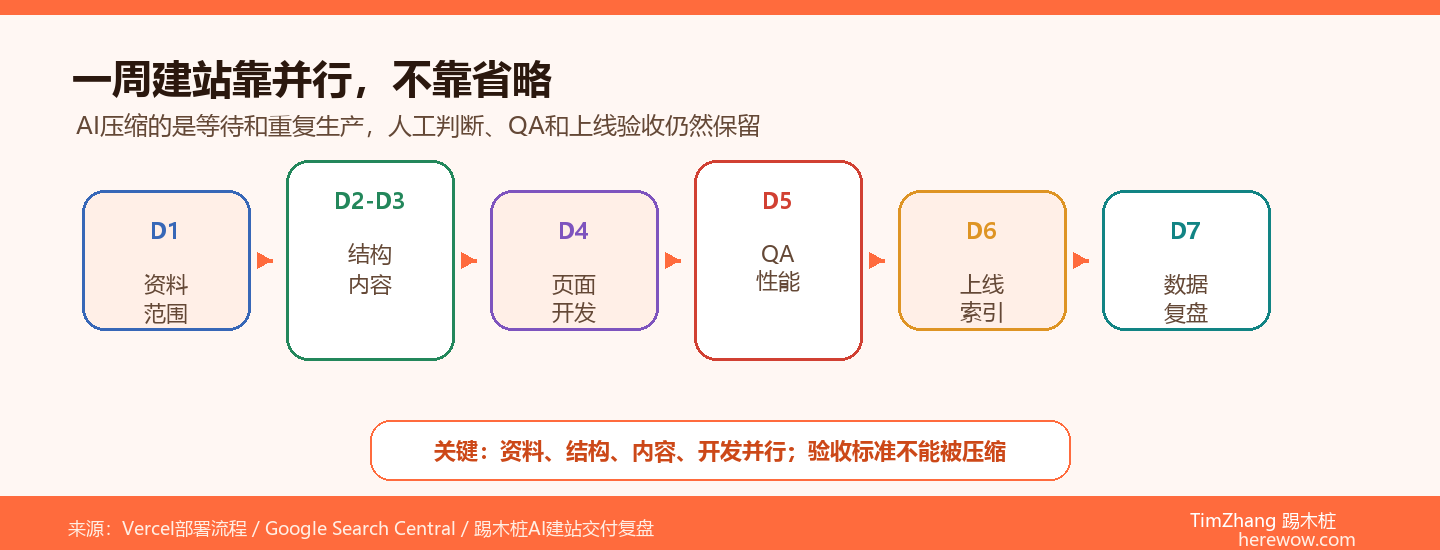
核心要点
- 裸Prompt每次都要重新解释规则
- AI Skill把品牌、来源和QA固化成流程
- 节省70%来自减少返工,不是减少判断
- 最终业务边界仍然需要人工负责
裸用ChatGPT做内容校对,最大的浪费不是模型回答不够快,而是每次都要重新解释规则:品牌语气是什么,哪些外链能用,FAQ不能写什么,图片文字不能出框,内链该放在哪里,正文要不要保留H1,发布后怎么检查。解释一次不难,批量写50篇、100篇,重复解释就会变成巨大的隐性成本。
OpenAI的提示工程指南强调清晰指令、上下文和任务拆解;File Search工具文档也说明模型可以结合外部文件检索上下文。AI Skill的本质,就是把这些上下文和规则从一次性Prompt里拿出来,变成可复用的工作流。
TimZhang踢木桩做博客写作Skill定制时,重点不是写一个漂亮提示词,而是把品牌资料、写作规范、来源库、视觉规范、发布格式和QA规则整理成能长期执行的系统。
Prompt为什么越用越乱
普通Prompt适合单次任务,比如“帮我润色这段话”或“检查错别字”。但内容校对不是单点任务。它同时涉及事实、来源、结构、语气、SEO、GEO、内链、图片、FAQ、CTA和发布格式。把这些要求全部塞进一次性Prompt,结果通常是前面规则记住了,后面规则漏掉了;这次检查了外链,下次忘了图片;这篇语气对了,下一篇FAQ污染了。
Google的生成式AI内容说明指出,是否使用AI不是关键,关键是内容是否对用户有帮助。有帮助内容文档同样要求内容满足真实读者需求。裸Prompt的问题在于,它很难稳定地把这些原则落到每篇文章的具体检查项上。
校对不是找错字,而是守住内容边界
对B2B出海内容来说,错别字只是最低层问题。更重要的是:有没有虚构客户案例,外链是否支撑段落论点,FAQ是否回答真实买家问题,CTA是否自然,图片文字有没有溢出,文章是否只是泛泛总结。裸Prompt容易停留在语言润色,Skill则可以把这些边界写成强制检查。
AI Skill到底省在哪里
以一批20篇中文B2B文章为例,如果每篇用裸Prompt校对,需要人工先复制规则、补充上下文、检查输出遗漏、再人工二次检查,保守估计每篇35分钟。换成Skill后,品牌规则、来源白名单、HTML结构、FAQ污染检查、图片规格和发布QA已经前置,人工主要处理红线问题和业务判断,每篇可能降到10到12分钟。
这个推算不是通用承诺,而是说明节省来源:不是AI突然更聪明,而是重复解释减少了。按20篇计算,裸Prompt约700分钟,Skill流程约220到260分钟,节省区间约63%到69%。如果原流程返工更重,接近70%是合理的;如果团队本来就有成熟编辑规范,节省幅度会更小。

节省的时间应该用于判断,而不是继续堆产量
如果用Skill省下时间后,只是生产更多泛泛文章,价值会很快耗尽。更好的用法,是把时间投向人工更擅长的部分:补充产品事实、采访销售、整理客户问题、判断标题承诺、筛选案例证据、复查高风险表述。这些判断不能完全交给模型。
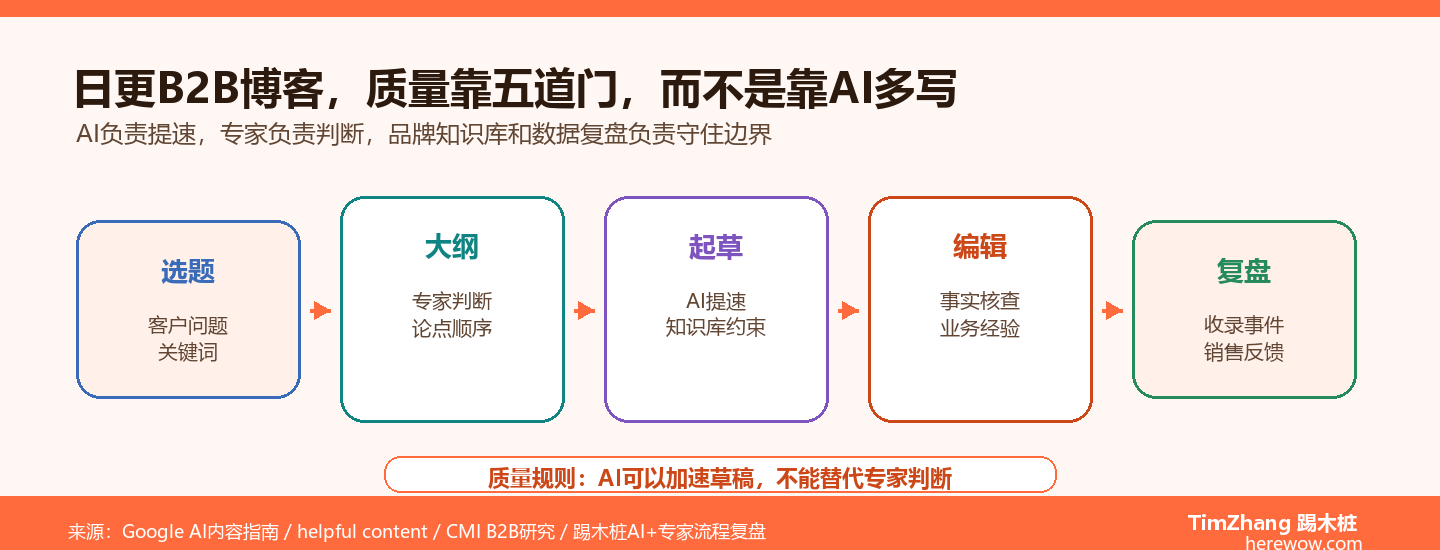
一个合格Skill至少包含六类规则
第一类是品牌规则:语气、禁用词、业务边界、服务页和CTA方式。第二类是来源规则:哪些官方文档能引用,哪些工具博客不加链接,外链必须嵌入正文。第三类是结构规则:核心要点、H2/H3、表格、FAQ、内链位置。第四类是事实规则:不虚构案例、不伪造数据、不夸大效果。第五类是视觉规则:PIL图片尺寸、底栏、文字不溢出。第六类是发布QA:源稿和站上内容都要检查。
企业数据使用说明提醒团队关注数据边界,NIST AI风险管理框架强调AI系统要可治理、可测量、可管理。把这些原则翻译到内容生产里,就是不要把Skill做成“万能写手”,而要做成有边界的质量系统。
来源和外链规则必须前置
最近很多AI内容的问题,不是没写链接,而是链接被集中堆在最后,或者引用无法支撑段落论点。Skill应该要求外链嵌入正文,并且每条来源服务当前段落的判断。删除某条来源后,如果段落逻辑不受影响,这条链接就只是装饰。
想看这套 AI 工作流的完整实操演示?
进群就有。群里每周拆解一个 AI 营销落地案例,从 Prompt 到产出全流程。
AI Skill和AI知识库不是一回事
AI知识库解决“模型知道什么”,AI Skill解决“模型怎么做”。知识库里放产品资料、案例、FAQ、术语表和客户问题;Skill里放写作步骤、校对规则、来源标准、图片规范和发布检查。只有知识库没有Skill,输出容易乱;只有Skill没有知识库,输出容易空。
这也是TimZhang踢木桩把AI知识库搭建和优质内容创作服务分开但联动的原因。先让AI理解业务,再让AI按正确流程执行,内容质量才会稳定。
从裸Prompt迁移到Skill的顺序
第一步,把过去反复修改的问题收集成清单。第二步,把品牌资料、服务页、案例、术语和禁用承诺整理成知识库。第三步,把写作和校对拆成阶段:选题、研究、初稿、来源、图片、FAQ、发布QA。第四步,给每个阶段写通过/失败标准。第五步,用一批旧文章回测,确认Skill能发现真实问题。
如果你的团队已经用AI写内容,但每篇都要人工大改,下一步不是换一个模型,而是让TimZhang踢木桩帮你把规则固化成选题与内容流程。这样AI才会从临时助手变成稳定生产系统。
一份可落地的Skill校对清单
Skill校对清单不要写成“提高质量”这种抽象要求,而要写成可判定问题。比如:正文外链是否嵌入论点所在段落;是否至少有两个服务或资源内链;图片是否只有一张且文字不出框;FAQ是否只存在于结构化字段;标题承诺是否在正文主体兑现;品牌名是否自然出现而不是只在结尾广告里。
第二层是证据检查。每个关键论点是否有来源、案例、计算或业务经验支撑;引用后是否解释了“所以怎样”;是否避免把工具博客当权威来源;是否没有虚构客户数据。第三层是发布检查:URL、分类、发布时间、封面、图片尺寸、站上内容节点和FAQ字段是否一致。
Skill要输出失败原因,而不是只给改稿
一个好Skill不应该只把文章改得更顺,而要指出为什么失败。比如“这条外链不支撑本段论点”“这张图的底栏文字过密”“这个FAQ回答的是编辑问题”“这个CTA没有说明读者要提交什么资料”。失败原因可积累,团队下次写作才会变强。
人工审核要集中在高价值判断上
Skill负责重复检查,人负责业务判断。人工审核应该重点看:标题是否夸大,服务承诺是否越界,案例是否真实,数据是否可解释,客户是否会关心这个问题。把人从格式、内链、字数和图片尺寸里释放出来,才是Skill节省时间的真正意义。
团队协作怎么改
引入Skill后,内容团队的分工会变化。市场负责人不再逐篇重写规则,而是维护品牌资料和质量线;编辑不再从零润色,而是处理Skill标出的高风险段落;销售不再只抱怨内容没用,而是把客户问题反馈进知识库;技术或运营负责发布和站上QA。
这种协作比“一个人写Prompt”复杂,但更稳定。裸Prompt依赖某个操作者的经验,操作者一换,质量就波动。Skill把经验写成流程,团队成员可以在同一标准下协作。对B2B出海企业来说,这比短期节省几小时更有价值。
Skill失效的三个信号
第一个信号是所有文章长得越来越像。说明Skill只固化了模板,没有固化判断。第二个信号是QA全部显示通过,但站上仍然出现图片溢出、外链堆在末尾或FAQ污染。说明Skill缺少发布后检查。第三个信号是内容越来越安全、越来越空。说明规则只会限制错误,没有鼓励原创推算、销售场景和业务证据。
解决办法不是把Skill写得更长,而是把失败样本喂回规则:哪些图不合格,哪些段落像AI,哪些来源无效,哪些CTA被销售忽略。TimZhang踢木桩维护写作Skill时,真正重要的不是一次性版本号,而是每次发布后的复盘和修正。
从一篇旧文开始回测
企业不需要一开始就为所有内容建立复杂Skill。最实际的做法,是拿一篇旧文章回测:让Skill检查标题承诺、正文结构、来源、内链、FAQ、图片和发布格式,再让人工编辑记录它漏掉了什么、误判了什么、哪些建议真的有用。三到五篇旧文回测后,规则会比凭空设计可靠得多。
回测时要保留失败样本。比如图片文字出框、外链集中在最后、FAQ重复正文、CTA太硬、内容没有原创推算。这些失败样本比成功样本更有价值,因为它们能转化成下一版Skill的硬性检查项。
不要让Skill变成写作借口
Skill能提高一致性,但不能保证选题一定正确。团队仍然需要判断客户是否真的关心这个问题,文章是否能承接服务,内容是否有证据,发布后是否值得复盘。如果一个题目本身没有业务价值,再严格的Skill也只会生产一篇格式正确的低价值文章。
所以AI Skill应该和选题、知识库、销售反馈一起使用。先判断该不该写,再让Skill帮助写得稳定。TimZhang踢木桩更愿意把Skill看成内容团队的质量操作系统,而不是替代所有内容判断的自动按钮。
什么时候不要继续加规则
当Skill已经能发现主要错误,但文章仍然缺少洞察时,继续加格式规则没有意义。此时要补的不是“再检查一遍”,而是更多业务输入:客户问题、失败案例、报价边界、技术资料、销售反驳和市场差异。规则只能保证下限,业务材料决定上限。
一个成熟团队会把Skill维护分成两类:硬规则只处理红线和格式,软样例负责展示好文章是什么样。这样既能避免低级错误,又不会把所有文章压成同一个模板。
相关延伸阅读
常见问题
AI Skill和普通Prompt最大的区别是什么?
AI Skill一定比人工编辑好吗?
内容校对为什么会节省这么多时间?
企业从哪里开始搭建写作Skill?
关于作者

📌 这篇文章对你有帮助?你可能还需要:
群内已有 1000+ B2B 出海从业者,禁广告,纯干货交流