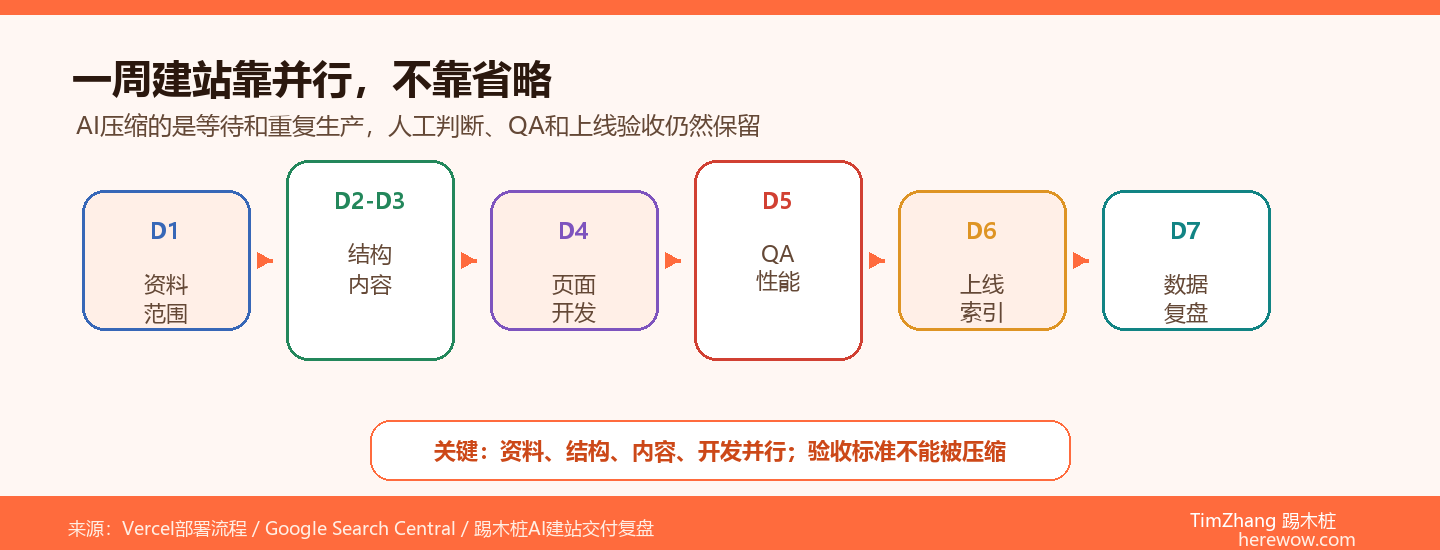
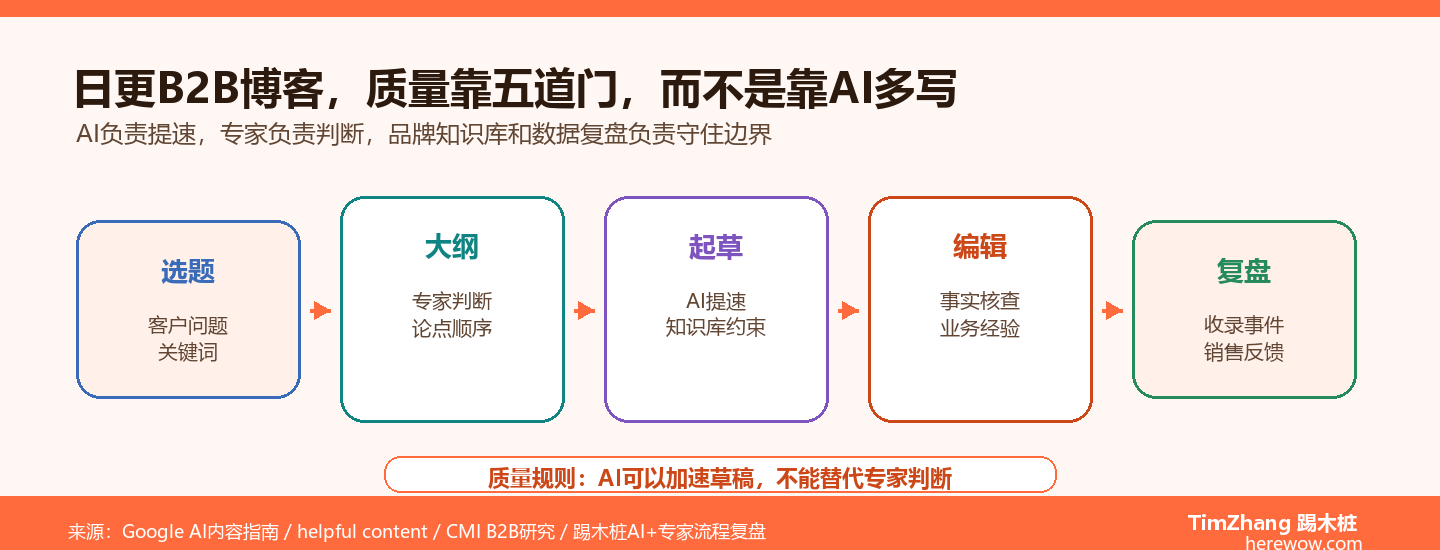
核心要点
- Claude vs ChatGPT不能只按文笔判断,要按任务类型选择
- 长文结构、资料理解、改写风格和工具生态各有差异
- B2B写作真正的瓶颈是业务输入和审核,不是模型名字
- 团队应建立任务分流规则,而不是争论唯一标准答案
Claude vs ChatGPT在B2B营销写作中的真实差异,不应该被简化成“谁写得更像人”或“谁更聪明”。对企业来说,更重要的问题是:这次任务是长文结构、服务页改写、销售邮件、资料整理、标题生成,还是多轮审核?不同任务需要不同模型特长,也需要不同输入和审核方式。
Anthropic的Claude文档和OpenAI的文本生成文档都说明,大模型能力要通过任务、上下文和使用方式发挥。模型差异当然存在,但B2B营销写作的稳定性,更多取决于资料、提示词、知识库和审核流程。
TimZhang踢木桩在做博客写作Skill和AI内容流程时,不会把团队绑定到单一模型,而是先定义任务分流:哪些任务适合长文推演,哪些适合快速变体,哪些必须接知识库,哪些需要人工审核。
第一类任务:长文结构和论证推演
长文写作最重要的不是语句漂亮,而是论证顺序。文章开头要回答读者主问题,中段要解释机制,后段要给决策路径。Claude和ChatGPT都能写长文,但不同团队会感受到结构、展开、语气和可控性的差异。真正的评估方式,是让它们处理同一份业务资料,而不是比较随机题目。
Anthropic的提示词工程指南强调清晰指令和上下文,OpenAI的提示词工程文档也强调结构化输入。长文比较必须在同一输入条件下进行:同一标题、同一资料、同一外链、同一字数、同一审核标准。
长文评估要看返工点
不要只看初稿读起来顺不顺。要记录返工点:标题承诺是否兑现,H2是否递进,外链是否支撑论点,品牌CTA是否自然,FAQ是否重复正文,是否虚构案例。谁的返工少,谁在当前任务里更适合。
第二类任务:服务页和销售资料改写
B2B服务页改写比博客更接近商业结果。模型要理解服务边界、目标客户、证据、CTA和风险。Google关于有用内容的原则提醒,内容要帮助真实用户完成判断。服务页改写如果只变得更顺口,却没有更清楚地回答客户为什么选择你,就不算成功。
在这类任务中,模型差异往往不如知识库差异重要。一个带有客户问题、案例、服务边界和禁用表达的品牌AI知识库,会比单纯换模型更能提升输出质量。模型负责语言和结构,知识库提供业务判断。

销售资料更看重可转发性
销售邮件、FAQ和案例摘要的评价标准不是文学性,而是销售敢不敢转发。内容要准确、短、边界清楚、下一步明确。模型如果写得很华丽,但销售需要大量删改,就不适合这类任务。
第三类任务:资料整理和多版本改写
AI写作不只是生成文章,还包括资料整理、会议摘要、问答提取、短帖改写、标题变体和多语言草稿。Microsoft的Work Trend Index强调AI会改变组织工作方式,这些小任务往往比单篇长文更频繁。
Claude和ChatGPT在不同小任务中的体验可能不同。企业不需要争论谁全局更好,而应该建立任务清单:哪一个模型更适合长资料整理,哪一个更适合快速变体,哪一个更适合接工具或自动化,哪一个更适合团队现有工作流。
第四类任务:事实、来源和审核风险
NN/g关于AI幻觉的提醒适用于所有模型。无论Claude还是ChatGPT,都可能生成错误引用、过度承诺、虚构案例或不准确结论。模型选择不能替代事实审核,尤其是涉及价格、认证、交期、客户案例和效果数据时。
Google关于生成式AI内容的说明也提醒,AI参与不改变内容质量责任。B2B团队应建立审核清单,而不是把“用了哪个模型”当成质量背书。真正的质量来自业务资料、来源、人工判断和复盘。
想看这套 AI 工作流的完整实操演示?
进群就有。群里每周拆解一个 AI 营销落地案例,从 Prompt 到产出全流程。
比较模型要用同一套评分表
建议评分维度包括:结构清晰度、业务准确性、来源相关性、品牌语气、销售可用性、返工时间、幻觉风险、内链和CTA自然度。每项1到5分,连续测试10个真实任务,比一次主观体验更可靠。
团队如何制定模型分流规则
可以先用30天测试:选10个真实任务,包括长文、服务页、邮件、FAQ、社媒和数据摘要。每个任务分别用Claude和ChatGPT生成,记录输入、输出、返工和最终使用情况。不要只保存优秀样稿,也要保存失败样本,因为失败样本能告诉你哪类任务需要更多约束。
McKinsey的State of AI强调AI落地要关注流程和治理。模型分流也应该成为流程:谁选择模型,谁维护Prompt,谁审核输出,谁把错误写回知识库。没有流程,模型切换只是工具焦虑。
如果你的团队在Claude和ChatGPT之间反复切换,却没有稳定产出,可以让TimZhang踢木桩先做AI内容创作流程和选题规划。先把任务和审核定义清楚,再比较模型,判断会更客观。
不要把模型评测写成品牌信仰
很多团队比较Claude和ChatGPT时,很容易变成偏好争论。有人喜欢Claude的长文语气,有人喜欢ChatGPT的工具生态,有人只看某一次输出。更可靠的做法是把模型评测变成任务实验,而不是品牌信仰。
实验要保留同一输入、同一资料、同一审核人和同一评分表。每次任务都记录最终采用哪个输出、为什么采用、修改了多久、销售是否能用。30天后你会得到任务分流规则,而不是一句“哪个模型更好”。
模型还会持续更新,所以分流规则也要定期复查。不要把一次测试结论写死,也不要每周追新模型。对B2B团队来说,稳定流程比追逐每次模型升级更重要。
不同任务的模型选择样板
可以把B2B写作任务分成五类。第一类是长文结构,重点看论证顺序和段落递进。第二类是服务页改写,重点看服务边界和CTA。第三类是销售资料,重点看准确、短、可转发。第四类是社媒变体,重点看速度和品牌声音。第五类是数据摘要,重点看是否能保留事实和限制。
每一类任务都可以分别测试Claude和ChatGPT。不要只看单次输出,而要记录返工时间、审核意见和最终是否发布。模型分流规则最好来自这些记录,而不是来自工具宣传或个人偏好。
对比时要防止输入不公平
如果给一个模型更多背景资料,另一个模型只有标题,对比结果当然不可靠。测试时要保持输入一致,包括目标读者、资料、外链、字数、语气和禁用表达。只有输入一致,输出差异才有参考价值。
模型差异之外,还有团队差异
同一个模型,在不同团队里表现会不一样。原因是知识库、Prompt模板、审核人、服务页结构和销售反馈都不同。一个团队觉得某模型好用,可能只是它的Prompt更适合那个模型;另一个团队觉得不好用,可能是业务资料没有整理。
因此,企业不能把外部评测结论照搬到自己的工作流。外部评测可以提供参考,但内部真实任务测试更重要。尤其是B2B营销写作,内容必须贴合产品、客户、服务边界和销售动作。
如何处理模型更新带来的变化
模型会更新,团队的分流规则也要轻量复查。建议每季度抽取5个代表性任务重新测试,观察是否有明显变化。若某模型在某类任务中的返工明显减少,再调整规则;如果只是体验略有不同,不必频繁改变流程。
频繁切换模型会带来隐性成本:团队要重新适应输出风格,Prompt模板要调整,审核标准要重新校准。除非变化能显著降低返工或提高质量,否则稳定流程通常比追新更重要。
最终比较的是系统,不只是模型
真正决定B2B写作质量的,是模型、知识库、Prompt、审核和发布流程组成的系统。Claude和ChatGPT只是系统中的一环。没有知识库,再强模型也会空泛;没有审核,再顺的文案也可能出错;没有网站承接,再好的文章也难转化。
因此,模型比较的结论应该写成系统改进建议:哪些任务继续用现有模型,哪些补知识库,哪些改Prompt,哪些必须人工审核,哪些需要服务页承接。这样比较才会帮助团队产出,而不是制造工具焦虑。
模型分流也要考虑数据安全和权限
比较模型时,团队还要考虑哪些资料可以输入,哪些资料只能内部处理。客户名单、报价、未公开案例、合同细节和敏感技术资料,不应该随便复制到聊天窗口。不同工具和账号的权限、数据设置和企业策略,都要进入流程。
因此,模型分流规则里要有资料分级:公开资料可以用于常规写作,内部资料只用于受控环境,高风险资料只做人工摘要或脱敏后使用。这个规则比“哪个模型文笔更好”更重要,因为B2B内容经常连接真实客户和商业信息。
如果没有权限边界,AI写作效率越高,泄露和误用风险也越高。
模型评测还要考虑团队能不能长期维护。一个模型短期效果好,但需要复杂提示词和大量人工救稿,未必适合小团队;另一个模型输出朴素,但返工稳定、容易接入流程,可能更适合日常生产。B2B营销写作不是模型演示,而是持续交付。
最终的选择应该写成流程文件:哪类资料能输入,哪类任务用哪个模型,谁审核,错误如何记录,什么时候复测。只有这样,Claude vs ChatGPT的比较才会变成组织能力,而不是工具偏好或聊天经验。团队要能解释为什么这样分流,也要能在模型变化后重新验证。
相关延伸阅读
常见问题
Claude和ChatGPT哪个更适合B2B长文?
B2B企业是否需要同时使用两个模型?
模型选择能解决AI写作空泛问题吗?
如何客观评估Claude和ChatGPT?
关于作者

📌 这篇文章对你有帮助?你可能还需要:
群内已有 1000+ B2B 出海从业者,禁广告,纯干货交流