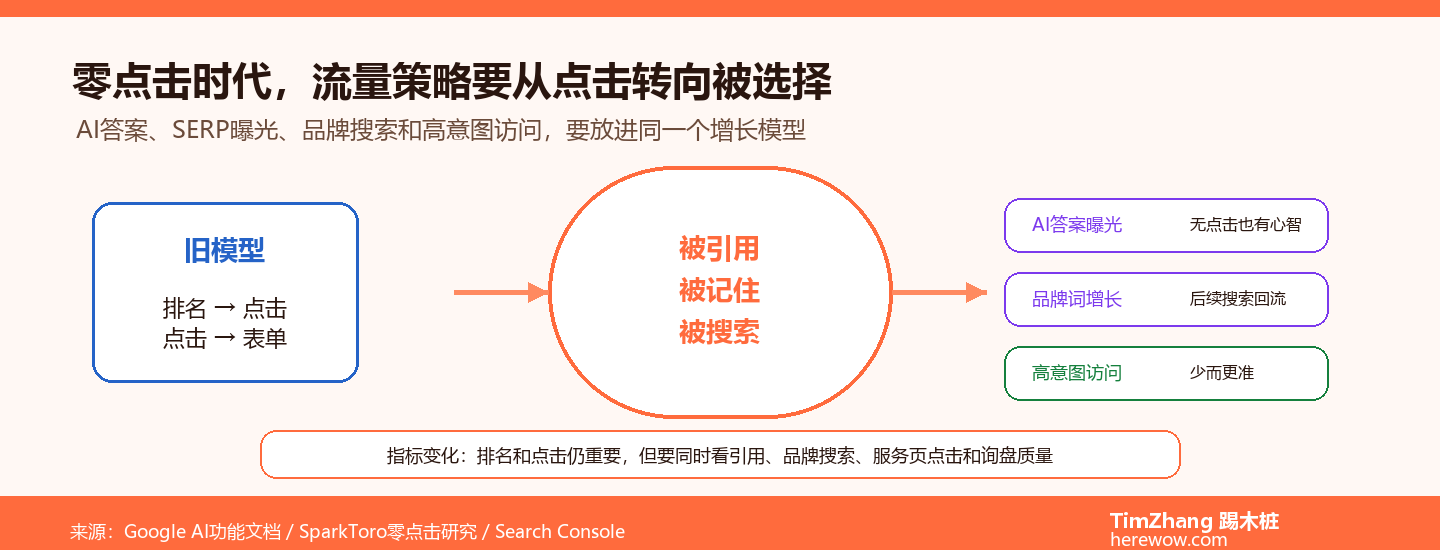
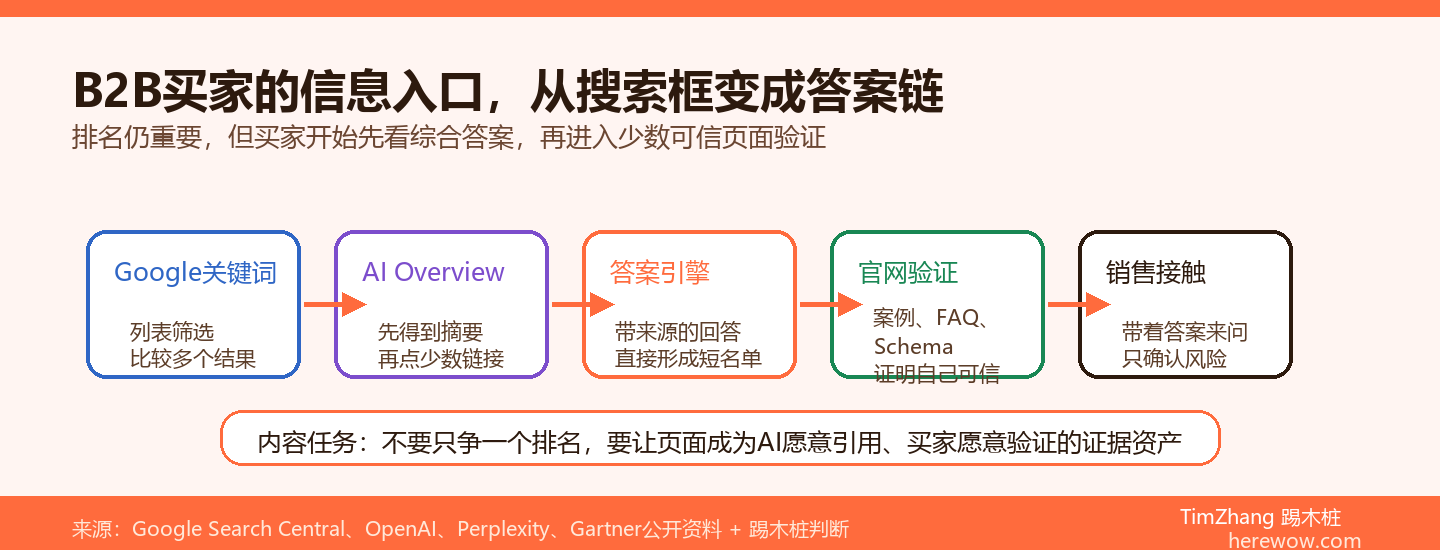
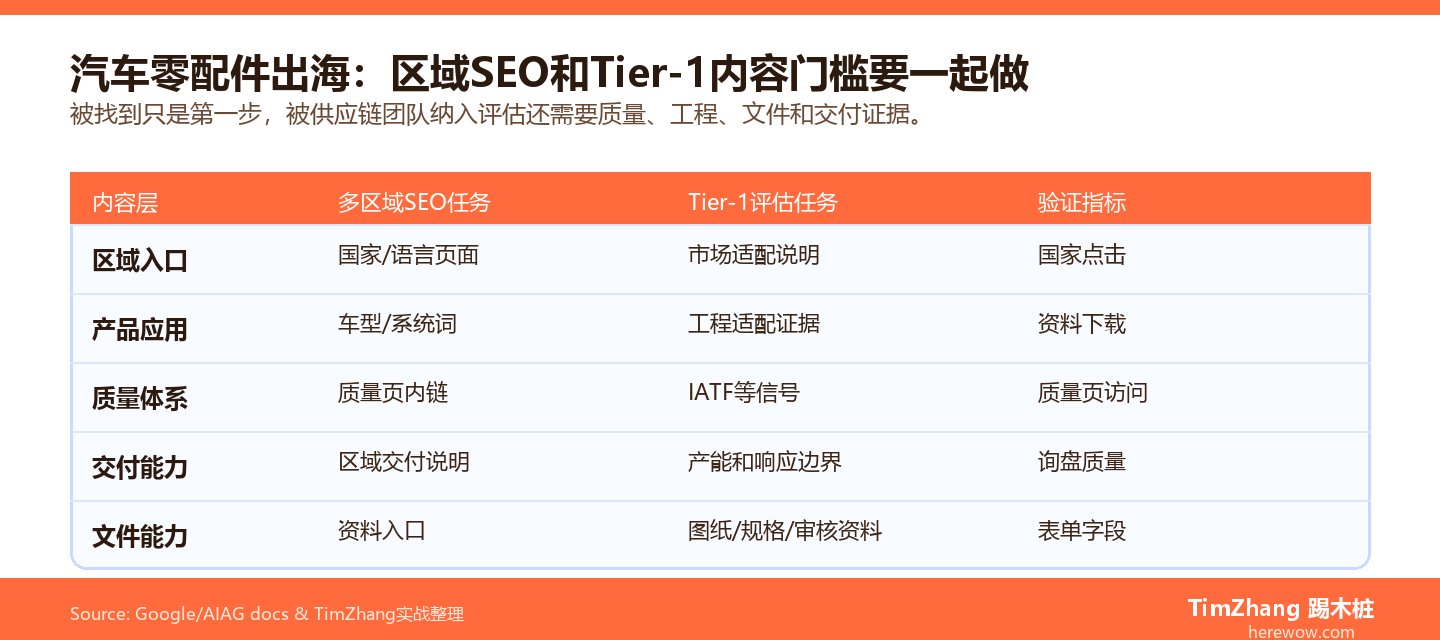
很多B2B出海企业已经部署了Schema结构化数据——JSON-LD脚本贴上去了,Google Rich Results Test也通过了,但就是没看到AI搜索引擎(Perplexity、Google Gemini、ChatGPT)引用自己的内容。
"我已经加了Schema,为什么AI还是看不到我?"这个问题在过去半年被我们的客户反复问到。为了找到答案,我们系统性地排查了30个已部署Schema但AI引用率几乎为零的B2B网站,逐一检查它们的结构化数据质量。
结果发现:问题几乎从来不是"没有Schema",而是Schema的质量、深度和上下文不足以让AI引擎有效识别和理解。
核心要点
- Schema覆盖率不足是首要问题——30个网站中27个仅标记了1-2种schema类型,而AI引擎需要完整的实体关系网络
- Schema与页面内容不一致是最隐蔽的杀手——标记的数据和页面上实际展示的信息存在偏差,触发信任降级
- 实体关系断裂导致AI无法建立完整的知识图谱——缺少author→Person→Organization的关联链
我们怎么排查的
排查方法很简单但很彻底:对每个网站,我们提取了所有JSON-LD数据,对照Google Structured Data Testing Tool和Schema.org规范逐项检查。同时,我们在Perplexity和Google Gemini中搜索该网站覆盖的核心关键词,记录引用情况。
然后,我们将30个网站按"Schema已部署但AI零引用"vs"Schema已部署且AI有引用"分为两组做对照。前一组24个网站,后一组6个网站。以下是我们发现的5个系统性差异。
原因一:Schema类型覆盖太浅——只做了"入门级"标记
现象:装了插件就算完成了
这是最普遍的问题。30个网站中,27个的Schema部署停留在"安装了WordPress SEO插件、勾选了几个基本选项"的阶段。最常见的配置是:首页标记了Organization,产品页标记了Product,博客文章标记了Article。看起来"都有",但实际上远远不够。
根据HTTP Archive 2024年对1690万网站的分析,JSON-LD的采用率已达到41%。但采用率不等于覆盖深度——就像我们的样本中100%部署了Schema,但80%的覆盖深度不足以被AI有效识别。
AI引擎需要什么样的Schema深度
AI引擎在理解一个网页时,不是简单地读取某个schema类型,而是通过实体关系网络建立对页面内容的整体理解。一个只标记了Product的页面,对AI来说只是一个"产品实体"。但如果这个Product连接了brand(品牌)、manufacturer(制造商,连接到Organization)、offers(报价,连接到Offer)、review(评价)和additionalProperty(技术参数),AI就能建立一个丰富的产品知识图谱。
Search Engine Journal的分析指出,结构化数据正在"从SEO工具演变为AI发现的基础设施"(原文:from an SEO tool to a critical enabler for machine understanding)。这意味着浅层的Schema标记在AI搜索时代的效果会越来越差。
如果你的网站需要全面的Schema覆盖评估,网站健康诊断可以帮你快速定位结构化数据的覆盖缺口。
原因二:Schema数据与页面内容不一致
现象:标记的和展示的不是同一回事
这是排查中最让我们意外的发现。30个网站中,有11个存在Schema数据与页面可见内容不一致的问题。具体表现为:
价格不一致:Schema中标记的price是"$500",但页面上显示的是"联系我们获取报价"。AI引擎在交叉验证时发现矛盾,会降低对该数据点的信任度。
作者信息不一致:Schema中标记的author是一个Person实体(含姓名和URL),但页面上没有显示任何作者信息,或者显示的是不同的名字。
产品规格不一致:Schema中标记的additionalProperty列出了10个技术参数,但页面上只展示了5个。AI引擎会认为剩余5个是虚假数据。
为什么AI引擎特别在意这种不一致
AI搜索引擎在处理结构化数据时,会将其与页面的自然文本进行交叉验证。BrightEdge的研究指出,结构化数据的作用是"帮助AI准确理解内容上下文"(原文:Schema helps AI accurately understand your content context)。当AI发现Schema声明的信息在页面文本中找不到对应内容时,它会认为这个schema标记是不可靠的,从而降低引用该来源的概率。
Google的Rich Results Test只能验证Schema的语法正确性,不能验证语义一致性。所以"通过了测试"不等于"数据是有效的"。
原因三:实体关系断裂——Schema中的"孤岛节点"
现象:各个Schema类型互不关联
第三个原因是前两个的延伸,但更加隐蔽。很多B2B网站的各个Schema类型是独立存在的——Article是一个孤立节点,Organization是另一个孤立节点,Product又是第三个。它们之间没有任何关联。
想知道你的网站基础问题在哪里?
加 Tim 微信,发送你的网站链接,Tim 会先看首页、结构、内容、SEO 基础和询盘路径,给你一份网站基础诊断和优化建议书。
对AI引擎来说,孤立的实体几乎没有价值。AI的知识图谱是通过实体之间的关系来建立理解的。一个Article如果能通过author关系连接到Person,再通过worksFor关系连接到Organization,再通过sameAs关系连接到LinkedIn资料页,就形成了一条完整的信任链。而一个孤立的Article,AI无法判断它的来源权威性。
缺失的关键关系
在我们的30个网站样本中,以下关系的缺失率最高:
| Schema关系 | 缺失率 | 影响 |
|---|---|---|
| Article → author → Person | 63% | AI无法评估内容创作者的专业度 |
| Person → worksFor → Organization | 77% | AI无法建立作者与机构的关联 |
| Organization → sameAs → [社交资料] | 70% | AI无法验证机构的真实身份 |
| Product → brand → Brand | 57% | AI无法建立产品与品牌的关联 |
HTTP Archive的数据显示,在全球范围内,Article → author → Person关系有92.5万个实施案例。但能继续延伸到worksFor → Organization的不到30%。这意味着即使是在全球范围内,大部分网站的实体关系链都在author这一步断裂了。
原因四:缺少内容层面的语义信号
现象:有了Schema但内容本身对AI不友好
第四个原因回到了内容层面。Schema是给机器看的"翻译",但如果原始内容本身就缺乏AI能理解和引用的信息结构,Schema再完善也白搭。
具体来说,被AI引用的B2B页面在内容层面有以下特征(而我们的30个样本普遍缺失):
清晰的问题-答案结构:AI引擎最喜欢引用的内容格式是"提出问题→给出明确答案→展开论述"。FAQ结构的页面被AI引用的概率远高于纯叙述性页面。
量化的数据点:AI引擎在生成回答时需要具体的数据支撑。页面中的百分比、数量、时间等可量化信息,比模糊的形容词更容易被AI抓取和引用。
权威的外部引用:正如我们在前面文章中讨论的,引用密度直接影响AI的引用决策。普林斯顿大学的GEO研究(KDD 2024)证实,包含引用和统计数据的内容在生成式引擎中的可见性显著更高。
Schema只能帮助AI"识别"你的内容结构,但不能让AI"想引用"你的内容。想让AI愿意引用你,需要在内容层面提供真正的信息增量。如果你的内容规划还没有考虑AI引用因素,可以了解一下我们的选题策划服务。
原因五:技术执行错误——Syntax问题伪装成了策略问题
现象:JSON-LD有语法错误但不知道
最后一个原因最"低级"但也最常见。30个网站中,有8个存在JSON-LD语法错误——属性名拼写错误、必填字段缺失、数据类型不匹配(如把数字写成了字符串)。这些问题在Google Search Console的"增强功能"报告中可以看到,但很多B2B网站管理者从不检查这个报告。
常见的技术错误包括:
@type拼写错误:写成"@type": "Prodct"而不是"Product"。整个Schema块因此失效,但页面不会报任何错误。
必填属性缺失:Product类型要求name和offers至少存在一个。如果两个都没有,整个Product标记会被忽略。
日期格式不规范:Schema要求ISO 8601格式的日期(如2024-03-15),但很多网站写的是March 15, 2024或2024年3月15日,导致datePublished属性无效。
嵌套结构错误:将author直接写成字符串"author": "Tim Zhang",而不是正确的Person实体"author": {"@type": "Person", "name": "Tim Zhang"}。虽然Google有时能容错处理,但AI引擎通常不能。
建议使用Google的Rich Results Test和Schema.org的官方验证工具对关键页面逐一检查。不仅要看"通过/失败",还要查看具体的警告信息——警告意味着数据虽被解析但不完整。
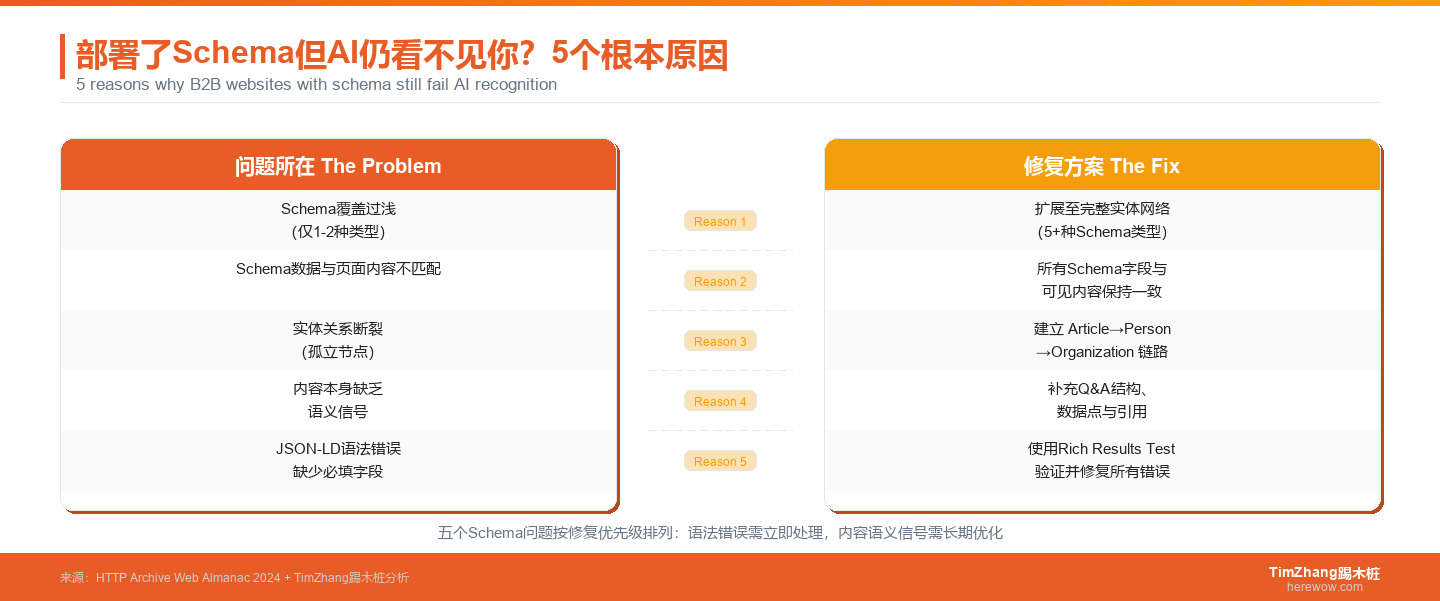
修复路线图:从AI不可见到AI可引用
基于以上五个原因,按优先级排列修复路线:
立即修复(本周):运行Google Rich Results Test,修复所有语法错误和必填字段缺失。这一步不花时间但效果立竿见影。同步检查Google Search Console的增强功能报告,处理所有错误和警告。
短期修复(两周内):统一Schema数据和页面可见内容。逐一检查核心页面的Schema标记,确认价格、作者、产品规格等字段和页面展示一致。不一致的地方以页面展示内容为准来调整Schema。需要更全面的技术诊断可以参考SEO/GEO优化资源。
中期优化(一个月内):扩展Schema覆盖深度,建立完整的实体关系网络。为所有内容添加author → Person → worksFor → Organization的关联链。为Organization添加sameAs链接到LinkedIn、官方社交媒体等外部身份验证。
长期策略(持续):在内容层面植入AI友好信号——清晰的问题-答案结构、量化的数据点、权威的外部引用。Schema是"翻译器",但内容本身是"原材料"。原材料的品质决定了翻译的效果。
Schema修复的执行判断
Schema不是给AI看的“捷径”,而是对页面真实内容的机器可读表达。页面没有展示的内容,不应该写进Schema;页面重要的实体,也不应该只出现在Schema里。
先统一实体,再扩展类型
很多B2B网站的问题不是Schema类型太少,而是Organization、Product、Article和FAQ之间没有稳定关系。先把公司、产品、页面和问题的关系串起来,再扩展更多类型。
测试工具通过后还要看内容证据
Rich Results Test只能证明基础语法,不代表AI能理解业务。最终仍要检查正文是否有定义、参数、案例、来源、FAQ和清晰的下一步承接。
Schema复盘不能只看插件后台。要用Google结构化数据文档校准类型和属性,用Rich Results Test检查基础语法,用Schema.org Product类型理解产品实体字段,再回到正文确认这些信息是否真实可见。
常见问题
通过Rich Results Test就一定能被AI识别吗?
B2B产品页应该部署哪些Schema?
Schema和GEO有什么关系?
修复Schema后多久能看到效果?
关于作者

📌 这篇文章对你有帮助?你可能还需要:
群内已有 1000+ B2B 出海从业者,禁广告,纯干货交流